Why Unify?#
“What is the point of unifying all ML frameworks?” you may ask.
You may be perfectly happy with the framework you currently use, and that’s great! We live in a time where great ML tools are in abundance, and that’s a wonderful thing!
Ivy just makes a wonderful thing even better…
We’ll give two clear examples of how Ivy can streamline your ML workflow and save you weeks of development time.
No More Re-implementations 🚧#
Let’s say DeepMind release an awesome paper in JAX, and you’d love to try it out using your own framework of choice. Let’s use PerceiverIO as an example. What happens currently is:
A slew of open-source developers rush to re-implement the code in all ML frameworks, leading to many different versions (a, b, c, d, e, f, g).
These implementations all inevitably deviate from the original, often leading to: erroneous training, poor convergence, performance issues etc. Entirely new papers can even be published for having managed to get things working in a new framework.
These repositories become full of issues, pull requests, and confusion over why things do or don’t work exactly as expected in the original paper and codebase (a, b, c, d, e, f, g).
In total, 100s of hours are spent on: developing each spin-off codebase, testing the code, discussing the errors, and iterating to try and address them. This is all for the sake of re-implementing a single project in multiple frameworks.
With Ivy, this process becomes:
With one line, convert the code directly to your framework with a computation graph guaranteed to be identical to the original.
We have turned a 4-step process which can take 100s of hours into a 1-step process which takes a few seconds.
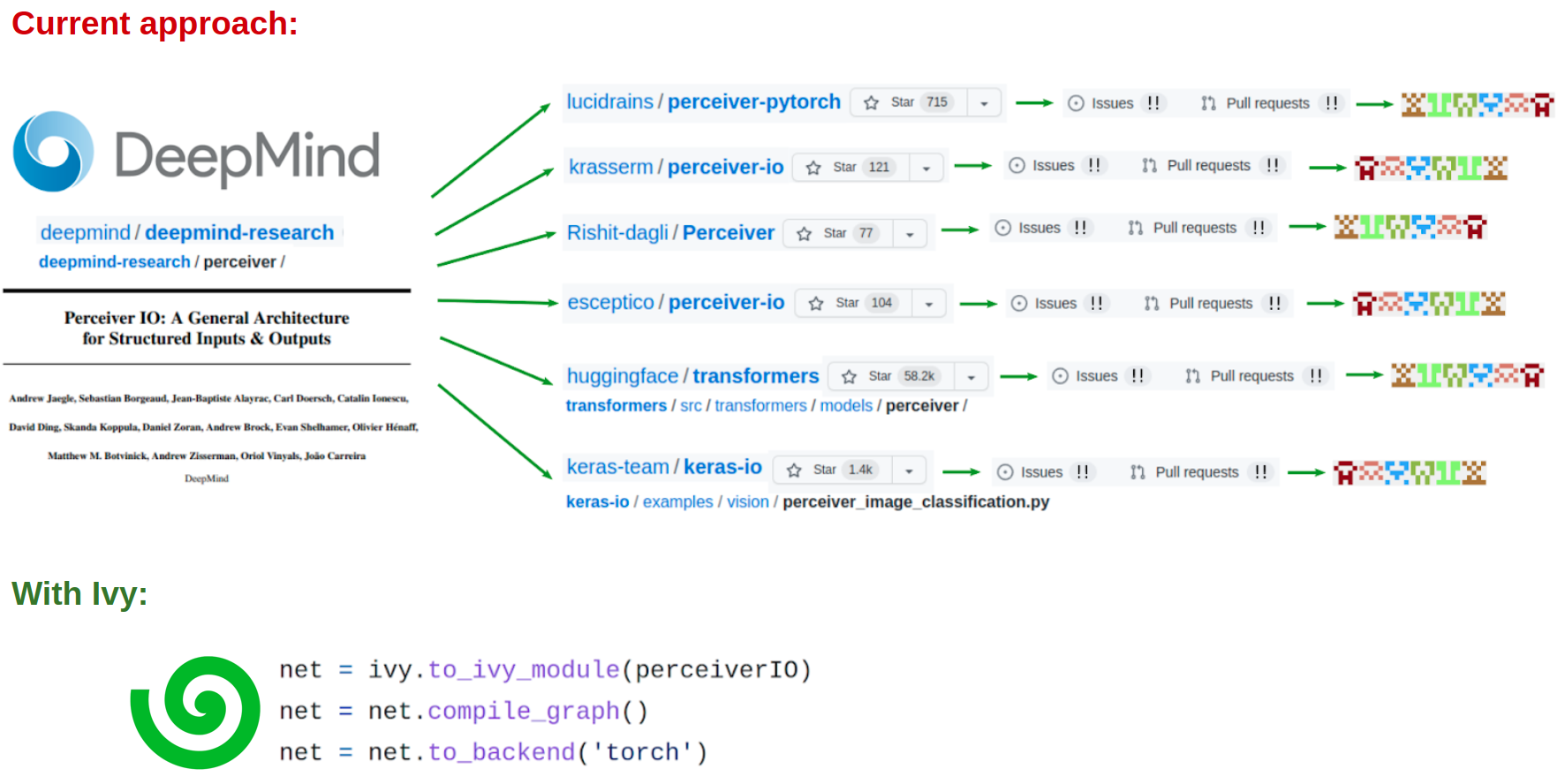
Taking things further, we can use this automatic conversion tool to open up all ML tools to everyone regardless of their framework.
“Infinite” Shelf-Life ✅#
Wouldn’t it be nice if we could write some code once and know that it won’t become quickly obsolete among the frantic rush of framework development?
A lot of developers have spent a lot of time porting TensorFlow code to PyTorch in the last few years, with examples being Lucid, Honk and Improving Language Understanding.
The pattern hasn’t changed, developers are now spending many hours porting code to JAX. For example: TorchVision, TensorFlow Graph Nets library, TensorFlow Probability, TensorFlow Sonnet.
What about the next framework that gets released in a few years from now, must we continue re-implementing everything over and over again?
With Ivy, you can write your code once, and then it will support all future ML frameworks with zero changes needed.
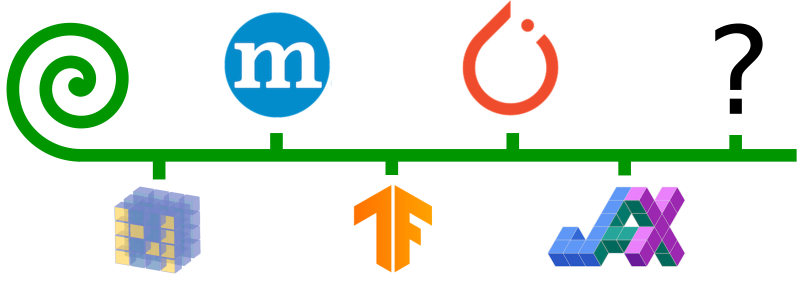
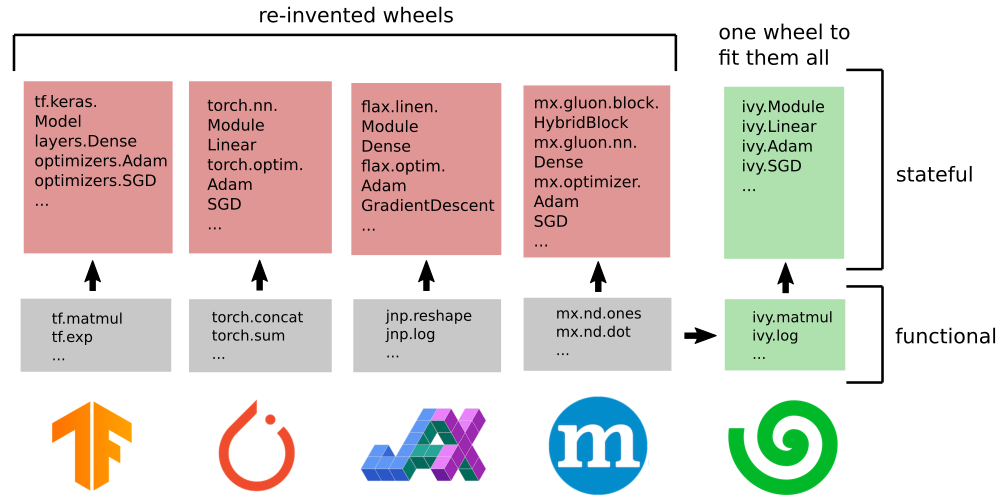
The same can be said about high-level code for: Modules, Optimizers and Trainers etc. Currently, the status quo is to continue implementing new high-level libraries for each new framework, with examples being: (a) Sonnet, Keras and Dopamine for TensorFlow (b) Ignite, Catalyst, Lightning, and FastAI for PyTorch, and (c) Haiku, Flax, Trax and Objax for JAX.
With Ivy, we have implemented Modules, Optimizers, and Trainers once with simultaneous support for all current and future frameworks.
Round Up
Hopefully, this has given you some idea of the many benefits that a fully unified ML framework could offer 🙂
Please reach out on discord if you have any questions!